
今回はIntelのNPUを使ってモンスター級の4bit量子化版Command R+ 104版を動かすことには成功したという事例紹介。ちなみに冒頭画像は検証環境であるドスパラのGALLERIA ZL7C-R38Hというノートパソコン。
動作環境と構築内容
ドスパラのGALLERIA ZL7C-R38Hというノートパソコンは発売開始後2年が過ぎた現在でも、世間的にはトップクラスのノートパソコンとなる。搭載されているNVIDIA RTX 3080 (VRAMは16GB)を利用した場合は快適に4bit量子化版Command R+ 104B版を利用できており、そのことはnote記事で報告済みだ。
ちなみに販売時は32GBメモリだったけれども、自己責任で64GBメモリへ換装してしまった。製品仕様は次の通りだ。
- インテル Core i7 12700H(Alder Lake)
- 画面サイズ:16 型(インチ)
- メモリ容量:64GB(32GBを換装)
- SSD:1TB
- GeForce RTX 3080 + Intel Iris Xe Graphics
- ビデオメモリ(VRAM):16GB
- 重量:2.15 kg
- サイズ:358x20x247 mm
- OS:Ubuntu 22.04 –> Win 11を入替え
ブログ記事のタイトルではNPUと書いたけれども、実はNPUというかは微妙だったりする。なぜなら14コアの第12世代インテルCore i7 12700H(Alder Lake)と書いた通りで、Intel ARCを搭載したCore Ultraシリーズ(Meteor Lakeだっけ?)ではない。
それから下記のような商品が存在するけれども、別に購入していない。非光沢つまりアンチグレアなので、自分の顔を見ずに済む。会社で業務用に支給されているVAIO Pro PK2とはエラい違いだ。

ともかく本題はRTX 3080を使わずしてCommand R+を利用することなので、実施した作業内容を紹介する。やることは単純で、2024年4月にサポートされたllama.cpp for SYCLを、GitHubの手順に従ってコンパイルするだけだ。
- 作業1:ドライバのインストール
- 作業2:oneAPIのインストール
- 作業3:Llama.cppのコンパイル
- 作業4:推論(生成)の実施
検証済み構成にCore i7 12700Hは含まれていなかってけれども、検証済みiGPUが “iGPU in i5-1250P, i7-1260P, i7-1165G7” だから大丈夫だろうと思って試してみたら、無事に動作してくれた。
なおEU(実行ユニット)数が80未満だと生成速度が遅くて使い物にならないとの注記があったけれども、こちらは96だから “ギリギリ” というところだろうか。
“If the iGPU has less than 80 EUs, the inference speed will likely be too slow for practical use.”
ちなみにNVIDIA GPUも利用可能とのことで、検証済み構成にはRTX 40 Seriesが記載されていた。ただし今回の目的はNVIDIA GPUに頼らない環境での検証が目的なので、こちらには手を出さなかった。もちろんDocker環境ではなく、ベアメタル環境だ。
ちょうど別件でUbuntu 22.04をインストールした後でNVIDIAドライバもCUDAもインストールしていない環境となっていたので、上記URLの説明に従って淡々とインストールを進めていった。
なおllama.cppをビルド(make)するところだけれども、推奨であるFP32のみ使用し、特に推奨されていないFP16は使用しない設定とした。これはLinkedinでIntel技術者によって紹介されている量子化版Llama 3のコンパイル内容を見ても、それで良さそうに感じている。
(技術的なことは分からないド素人なので、ここら辺はサル真似状態)
とりあえずデバイスは無事に表示されるので、いよいよ肝心の推論実行(生成実行)へと進むことにした。
実施結果
まず実行前にデバイス情報を指示に従って表示してみた。
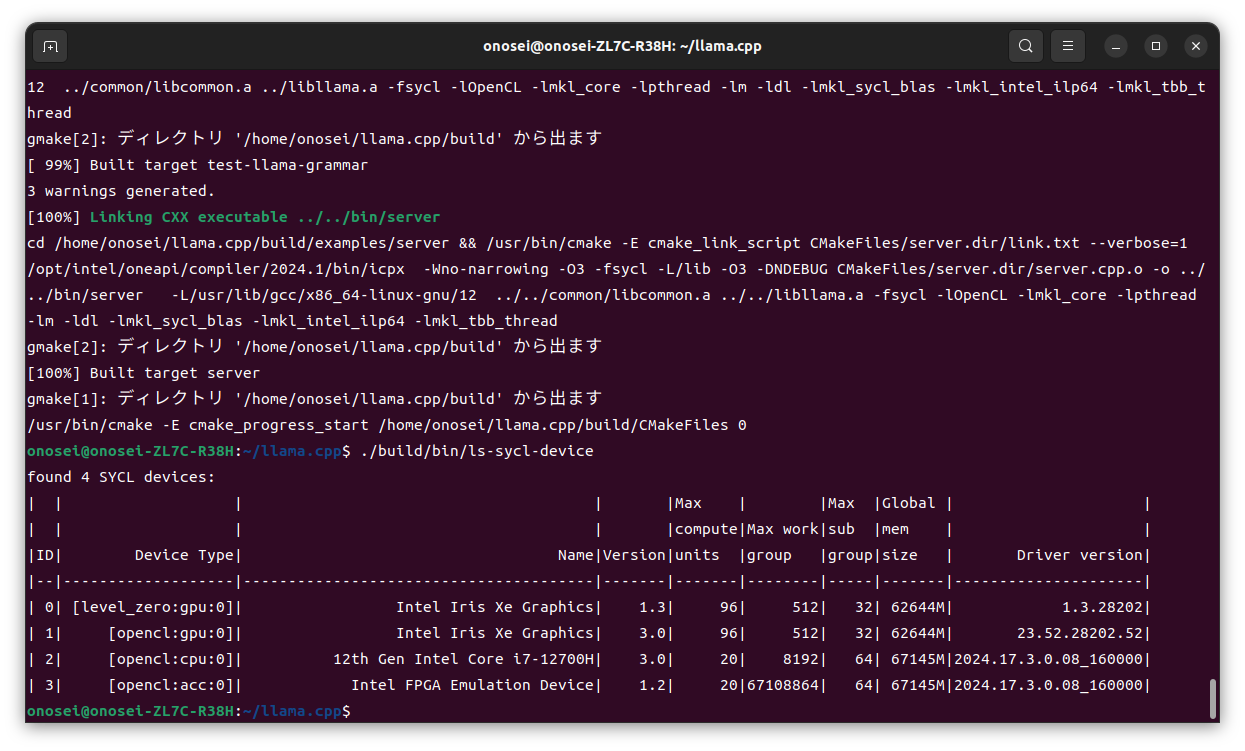
残念ながら我がGPU搭載ノートパソコンにはIntel ARCが搭載されていないので、レベル0で表示されるデバイスは1つだけだ。グローバルメモリサイズの62644という数字に一瞬だけ目を疑ったけれども、考えてみれば従来のIntel iGPUは共有メモリ方式だ。CPUメモリというか主メモリが64GBならば、特に不思議はない数字である。
なお残念ながら、UbuntuにはGPUメモリ使用量などをnvidia-smiコマンドのように表示してくれるツールは存在しない。Intelコミュニティを覗いてみたけれども、2023年9月時点のQ&Aでは存在しないとのことだった。それで今回は、intel_gpu_topコマンドのお世話になった。
(画面を見るとinstallがintallとなっているし、どうしてインストール作業で稼働状況が表示されるのだろうか? 自分でも疲れていたせいか、このあたりの記憶は定かではない)
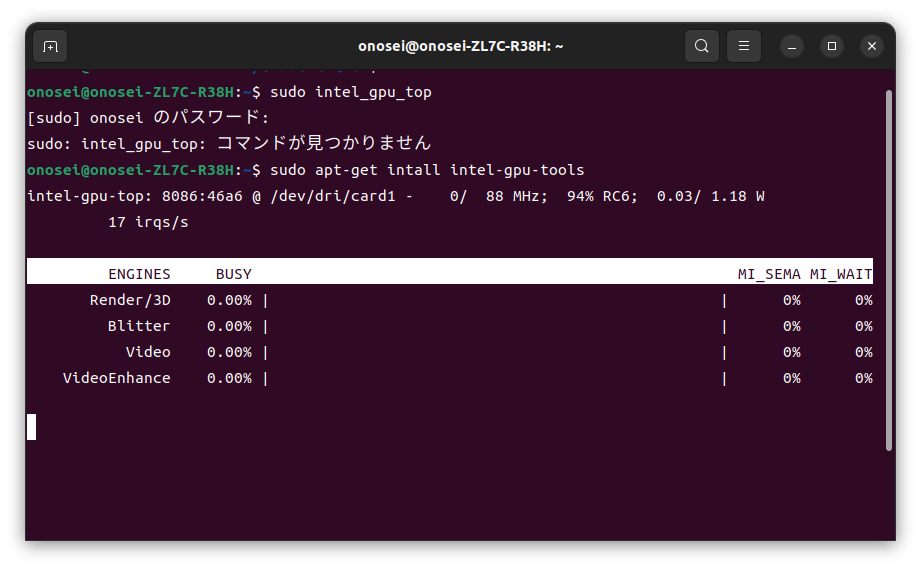
なお実行時の使用デバイスは、LinkedInと同じく “-sm layer” を選択した。なんだかすさまじく遅い処理だったけれども、もしかしたら使用デバイスを “-mg 0” としてNPUだけに指定すれば良かったのかもしれない。たぶん共有メモリゆえの実行速度の遅さだと思うけれども、機会があったら試してみたい。
“ZES_ENABLE_SYSMAN=1 ./build/bin/main -m ./models/command-r-plus-Q4_K_M-00001-of-00002.gguf -p “<|START_OF_TURN_TOKEN|><|USER_TOKEN|>ドラゴンボールのベジータを紹介してください<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>” –color -n 400 -e -ngl 15 -sm layer”
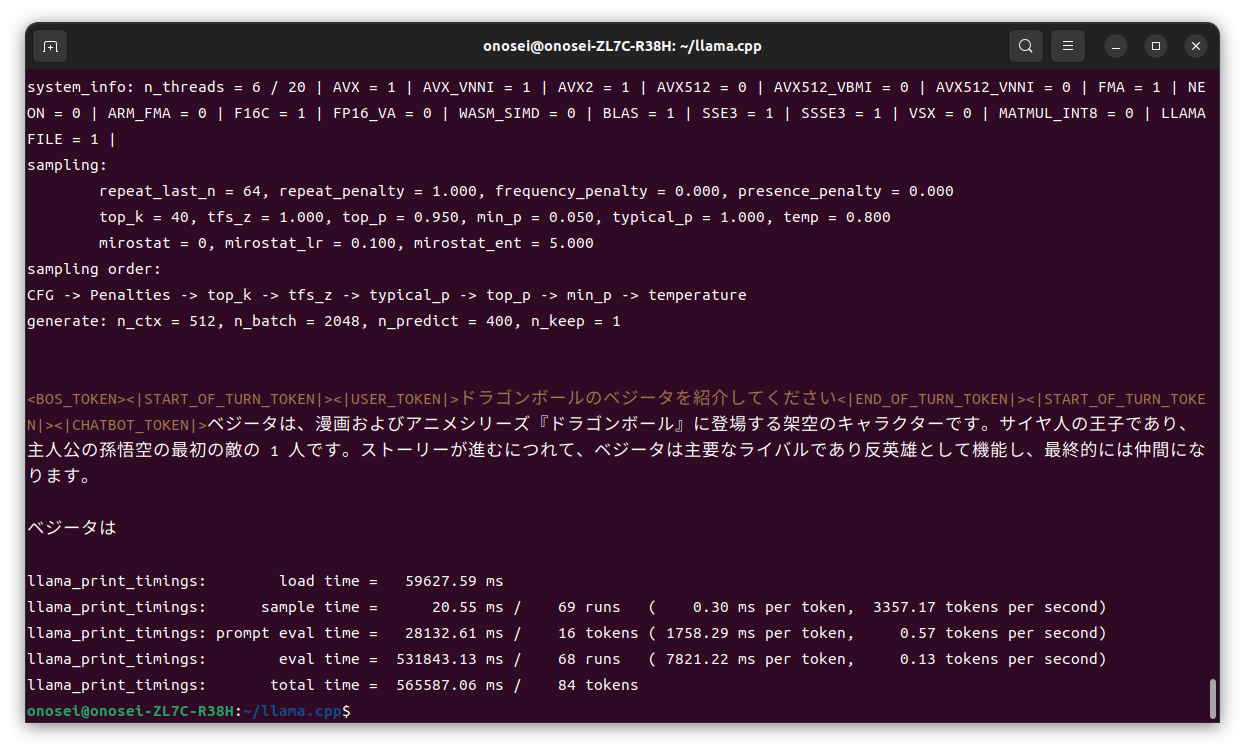
あまりに遅いのでCtrl + Cキーを叩いてしまったけれども、この出力結果から生成速度をご推察頂けるだろうか。ちなみにBLAS = 1と表示されているので、NPUは無事にGPUデバイスとして認識されているようだ。
なお “-ngl 25” で “-n 400 -e”、つまりVRAMにオフロードする層数のみを指定する方法でやると、約240分… 4時間がかりで最後まで出力することが出来た。
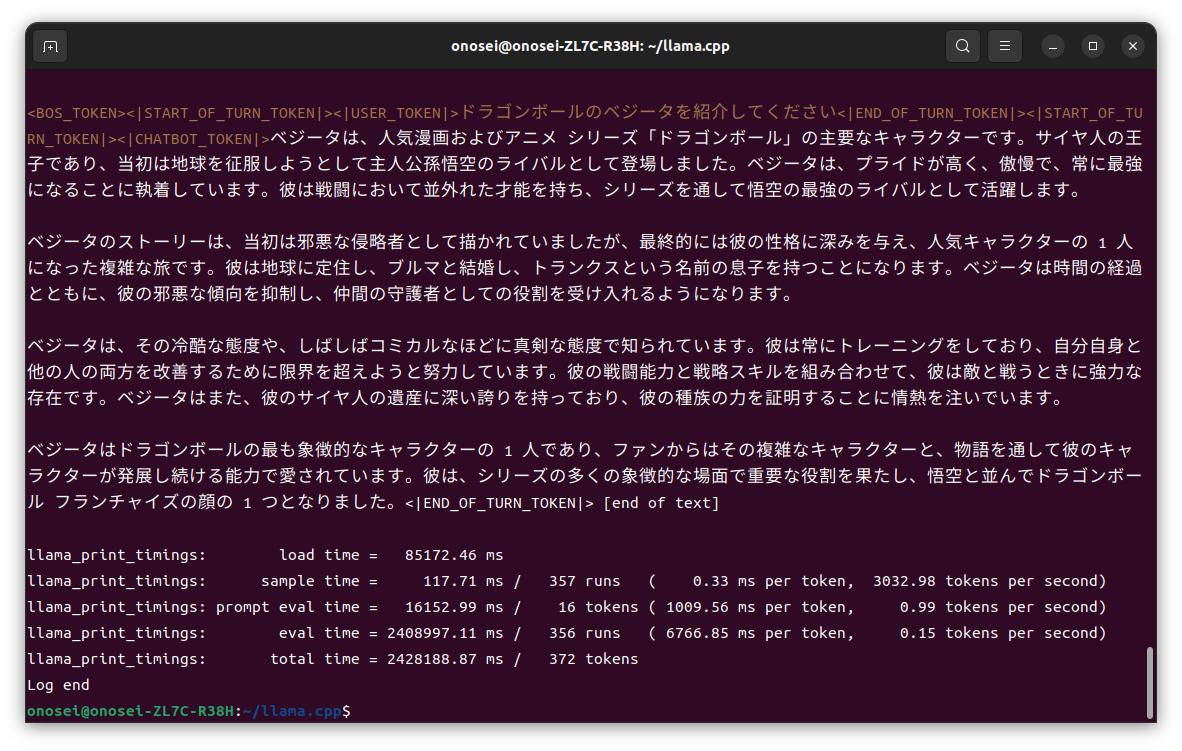
しめくくり
と、いう訳で、とりあえずIntel CPUに内蔵されているNPUを使用して、無事に動作することを確認することができた。
なおドスパラのガレリアにはIntel Arc A730M搭載パソコンも存在しており、それが欲しくなってしまったのは極秘事項である。

------
記事作成:小野谷静(オノセー)





